Padrões de projeto para softwares são soluções de eficiência já comprovadas e amplamente utilizadas para a resolução de problemas comuns em projeto de software. Estas soluções são desenvolvidas e conhecidas por especialistas e tornam-se padrões por serem reutilizadas várias vezes em vários projetos e por terem eficácia comprovada.
Os padrões de projetos tornam mais fáceis à reutilização de projetos e arquiteturas bem sucedidas. Expressando técnicas comprovadas como padrões de projetos tornam-os mais acessíveis aos desenvolvedores de novos sistemas. Os padrões de projetos ajudam você a escolher alternativas de projeto que tornam um sistema reutilizável. Padrões de projeto podem até mesmo melhorar a documentação e manutenção dos sistemas existentes, fornecendo uma definição explícita da classe e interações de objetos e suas intenções subjacentes. Simplificando, padrões de projetos ajudam designers a ter um modelo "correto" mais rápido.
Em geral, um padrão tem quatro elementos essenciais:
a) O nome do padrão é um identificador que podemos usar para descrever um problema de projeto, suas soluções e conseqüências em uma ou duas palavras. A nomeação de um padrão imediatamente aumenta o nosso vocabulário de design. Ela nos permite projetar em um nível maior de abstração. Ter um vocabulário de padrões permite-nos falar sobre eles com os nossos colegas, em nossa documentação, e até mesmo para nós mesmos. Ela torna mais fácil pensar em projetos e comunicá-las e suas vantagens e desvantagens para os outros. Encontrar bons nomes tem sido uma das partes mais difíceis do desenvolvimento de nosso catálogo;
b) O problema descreve quando aplicar o padrão. Ele explica o problema e o seu contexto. Poderia descrever os problemas de projeto específicos, tais como a forma de representar algoritmos como objetos. Poderia descrever classe ou objeto de estruturas que são sintomáticas de um projeto inflexível. Às vezes, o problema irá incluir uma lista de condições que devem ser atendidas antes que faça sentido aplicar o padrão;
c) A solução descreve os elementos que compõem o projeto, seus relacionamentos, suas responsabilidades e suas colaborações. A solução não descreve um projeto particular concreto ou de aplicação, porque um padrão é como um modelo que pode ser aplicado em muitas situações diferentes. Em vez disso, o padrão fornece uma descrição abstrata de um problema de projeto e um arranjo geral de elementos (classes e objetos no nosso caso);
d) As consequências são os resultados e trade-offs da aplicação do modelo. Embora as consequências sejam muitas vezes mudadas quando descrevemos as decisões de design, elas são críticas para avaliar alternativas de projeto e para a compreensão dos custos e dos benefícios da aplicação do padrão. Elas podem tratar de questões de linguagem e de execução, bem. Uma vez que a reutilização é frequentemente um fator de design orientado a objetos, as consequências de um padrão incluem seu impacto sobre a flexibilidade, a extensibilidade e a portabilidade de um sistema. A listagem dessas consequências explicitamente nos ajuda a compreender e avaliar.
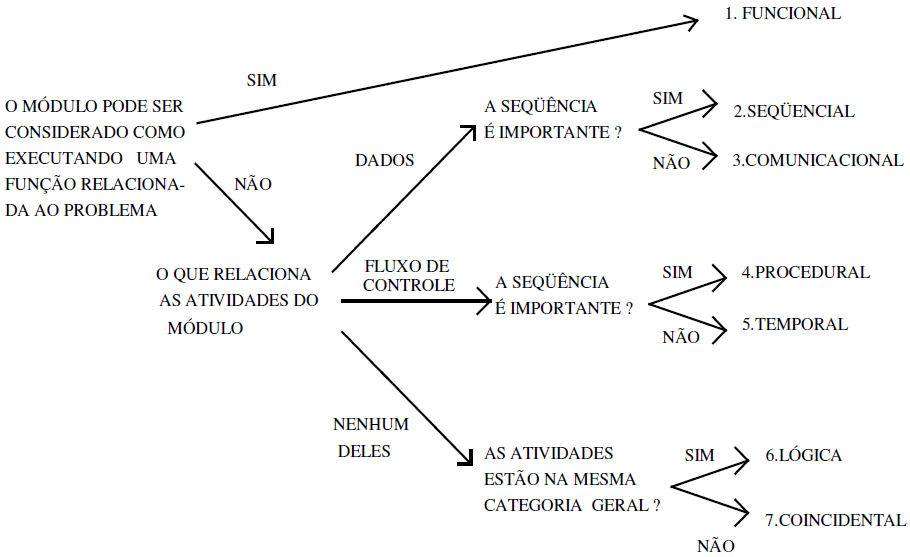
PRINCIPAIS PADRÕES DE PROJETO
Os padrões de projeto podem ser divididos por sua função ou por seu escopo, sendo apresentados em três categorias principais, quais sejam, padrões de criação, padrões estruturais e padrões comportamentais. Cada uma destas “categorias de padrões de projeto” contém os design patterns que são úteis a cada escopo.
Padrões Criacionais (Creational Patterns)
a) Abstract Factory (Fábrica Abstrata): Fornece uma interface para criar famílias de objetos relacionados ou dependentes sem especificar suas classes concretas.
b) Builder (Construtor): Separa a construção de um objeto complexo da sua representação para que o mesmo processo de construção possa criar diferentes representações.
c) Factory Method (Método Fabrica): Define uma interface para criar um objeto, mas deixa as subclasses decidirem qual classe instanciar. Factory Method permite que uma classe adie a instanciação para subclasses.
d) Prototype (Protótipo): Especifica o tipo de objetos a criar usando uma instância prototípica e cria novos objetos copiando este protótipo.
e) Singleton (Objeto Único): Certifica-se de que uma classe tenha somente uma instância e fornece um ponto global de acesso a ele.
Padrões Estruturais (Structural Patterns)
a) Adapter (Adaptador): Converte a interface de uma classe em outra interface esperada pelos clientes. Adapter permite que as classes trabalhem conjuntamente em casos que sem o adapter elas não poderiam por causa de interfaces incompatíveis.
b) Bridge (Ponte): Desacopla uma abstração de sua implementação de modo que as duas possam variar independentemente.
c) Composite (Compositor): Compõe objetos em estruturas de árvore para representar hierarquias parte-todo. Composite permite que clientes tratem objetos individuais e composições de objetos uniformemente.
d) Decorator (Decorador): Anexa responsabilidades adicionais a um objeto dinamicamente. Decoradores proveem uma alternativa flexível à herança para estender funcionalidade.
e) Facade (Fachada): Fornece uma interface unificada para um conjunto de interfaces em um subsistema. Facade define uma interface de alto nível que torna o subsistema mais fácil de usar.
f) Flyweight: Usa compartilhamento para suportar um grande número de objetos finos de forma eficiente.
g) Proxy (Procurador): Proporciona um espaço reservado para substituto ou outro objeto para controlar o acesso a ele.
Padrões Comportamentais (Behavioral Patterns)
a) Chain of Responsibility (Cadeia de Responsabilidade): Evita o acoplamento do remetente de uma solicitação ao seu destinatário, dando a um objeto a chance de processar o pedido à cadeia de objetos receptores e passa a solicitação ao longo da cadeia até que um objeto gere.
b) Command (Comando): Encapsula uma solicitação como um objeto, permitindo parametrizar clientes com diferentes solicitações, enfileirar solicitações ou registros, e apoiar as operações que podem ser desfeitas.
c) Interpreter (Interpretador): Dada uma linguagem, define uma representação para sua gramática juntamente com um interpretador que usa a representação para interpretar sentenças na linguagem.
d) Iterator (Iterador): Fornece uma maneira de acessar os elementos de um objeto agregado sequencialmente sem expor sua representação subjacente.
e) Mediator (Mediador): Defini um objeto que encapsula como um conjunto de objetos interage. Mediator promove o acoplamento fraco, evitando que objetos referenciem uns aos outros de forma explícita, o que lhe permite variar sua interação de forma independente.
f) Memento (Lembrança): Sem violar o encapsulamento, captura e externaliza o estado interno de um objeto para que o objeto possa ser restaurado para este estado mais tarde.
g) Observer (Observador): Define uma dependência um-para-muitos entre objetos de modo que quando um objeto muda de estado, todos os seus dependentes sejam notificados e atualizados automaticamente.
h) State (Estado): Permite que um objeto altere seu comportamento quando seu estado interno muda. O objeto parecerá ter mudado sua classe.
i) Strategy (Estratégia): Define uma família de algoritmos, encapsula cada um, e torna-os intercambiáveis. Strategy permite que o algoritmo varie independentemente dos clientes que o utilizam.
j) Template Method (Método Template): Define o esqueleto de um algoritmo numa operação, deixando alguns passos para subclasses. Template Method permite que as subclasses redefinam certos passos de um algoritmo sem alterar a estrutura do algoritmo.
k) Visitor (Visitante): Representa uma operação a ser realizada sobre os elementos de uma estrutura de objeto. Visitor permite que você defina uma nova operação sem alterar as classes dos elementos sobre os quais opera.
EXEMPLO DE PADRÃO DE PROJETO
Design Pattern Observer
O Design Pattern Observer define uma dependência um-para-muitos entre objetos de modo que, quando um objeto muda de estado, todos os seus dependentes são notificados e atualizados automaticamente. Considerando agora os princípios da Orientação a Objetos que nos diz para encapsular o que varia, dando prioridade à composição (implementação de interfaces) em relação à herança, é possível modelar os projetos levemente ligados entre objetos que interagem.
Aplicação Observer com Swing
Para esta aplicação, estão desenvolvidas 3 classes, cada uma abordando os conceitos de MVC, sendo respectivamente Model, View e Controller os nomes das classes. Para a implementação do Design Pattern, foi utilizado as classes-padrão da linguagem Java: java.util.Observable e import java.util.Observer. O diagrama implementado é o seguinte:
Pode-se observar no diagrama e na codificação da classe modelo que ela estende java.util.Observable, ou seja, ela será observada pelas classes View e Controller. Esta “observação” é criada quando na Controller é adicionada por meio do método addObserver(). Um detalhe importante é que as classes que “podem observar” necessariamente implementam a interface java.util.Observer.
Código da Classe Model:
import java.util.Observable;
public class Model extends Observable{
private String campo1;
private Integer campo2;
public void atualizar(String campo1, Integer campo2){
this.campo1 = campo1;
this.campo2 = campo2;
//Métodos que "avisam" os observadores
notifyObservers();
setChanged();
}
public String getCampo1(){
return campo1;
}
public void setCampo1(String campo1){
this.campo1 = campo1
}
public Integer getCampo2(){
return campo2;
}
public void setCampo2(Integer campo2){
this.campo2 = campo2;
}
}
Nas classes abaixo verifica-se o método update(), implementado devido a interface java.util.Observer. Este método é invocado quando a classe Observable, no caso deste projeto a View, invoca o método notifyObserver().
Código da Classe View:
import java.awt.GridLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.util.Observable;
import java.util.Observer;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JTextField;
public class View extends JFrme implements Observer{
private Model model;
private Jpanel pnlCampo1;
private JPanel pnlCampo2;
private JPanel pnlBotao;
private JLabel lblCampo1;
private JLabel lblCampo2;
private JTextField txtCampo1;
private JTextField txtcampo2;
private JButton botao;
public View(String titulo, Model model){
super(titulo);
this.model = model;
renderizarComponentes();
}
public void renderizarComponentes(){
pnlCampo1 = new JPanel();
pnlCampo2 = new JPanel();
pnlBotao = new JPanel();
lblCampo1 = new JLabel("Campo1:");
lblCampo2 = new JLabel("Campo2:");
txtCampo1 = new JTextField(20);
txtCampo2 = new JTextField(20);
botao = new JButton("Funcao");
pnlCampo1.add(lblCampo1);
pnlCampo1.add(txtCampo1);
pnlCampo2.add(lblCampo2);
pnlCampo2.add(txtCampo2);
pnlBotao.add(botao);
botao.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvvent e){
model.atualizar(txtCampo1.getText(),
Integer.parseInt(txtCampo2.getText()));
}
});
this.setLayout(new GridLayout(3,1));
this.add(pnlCampo1);
this.add(pnlCampo2);
this.add(pnlBotao);
this.setSize(300,300);
this.setVisible(true);
}
public void update(Observable o, Object arg){
this.setVisible(false);
}
}
A classe Controller implementa Observer, ou seja, ela será notificada quando houver qualquer mudança. A classe View (Observable) tem em seu método update() a exibição dos dados populados na classe View, sendo este método invocado quando o estado da Observable for modificado.
Código da Classe Controller:
import java.util.Observable;
import java.util.Observer;
public class Controller implements Observer{
private Model model;
private View view;
public static void main(String[] args){
new Controller();
}
public Controller(){
model = new Model();
view = new View("Camada Visão", model);
model.addObserver(this);
model.addObserver(view);
}
public void update(Observable o, Object arg){
System.out.println("O modelo contém os seguintes dados:");
System.out.println("Campo 1:"+ model.getCampo1());
System.out.println("Campo 2:"+ model.getCampo2());
}
}





































{kind=link}